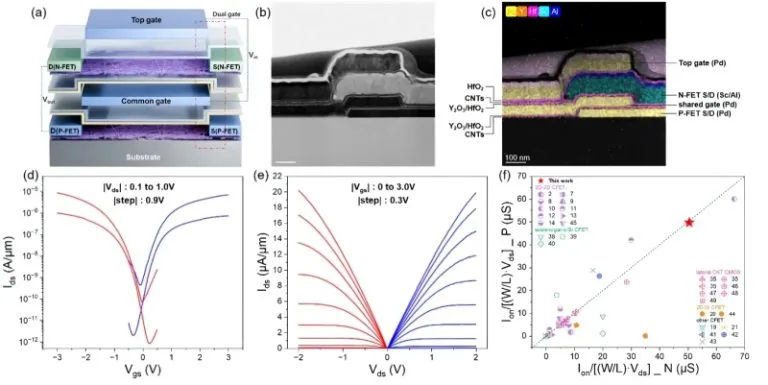
Advancements in CFET Technology Promise Faster, Smaller, and More Reliable Semiconductor Transistors
July 21, 2026
Leading semiconductor and AI technology company Nvidia has formally denied accusations that it utilized pirated book collections to train its artificial intelligence models. The company’s legal representatives addressed the matter in federal court in California, refuting claims linking Nvidia’s AI training data to unauthorized content from a well-known piracy repository.
The allegations centered around the suggestion that Nvidia had incorporated materials from Anna’s Archive, a repository known for distributing pirated literature, during the process of training AI systems. Nvidia’s attorneys argued these allegations lacked concrete proof and stressed that mere association or contact with the cached content does not constitute evidence of copyright infringement.
In their court statements, Nvidia’s legal team emphasized the absence of direct evidence connecting the company’s AI datasets to copyrighted works harvested without authorization. They maintained that Nvidia’s data acquisition for AI development adhered to legal norms and industry standards concerning copyrighted materials.
The dispute highlights growing concerns within the tech and legal communities over the sources of training data employed in developing advanced artificial intelligence. Companies using massive datasets face scrutiny over whether all components are properly licensed or fall under fair use provisions. Nvidia’s position points to the challenge of tracing origins for extensive datasets amid the vast digital landscape.
While detailed information regarding the specifics of Nvidia’s AI model training processes and dataset composition was not disclosed during the proceedings, the company’s rebuttal seeks to clarify that the piracy allegations are unsubstantiated. This defense aims to protect Nvidia’s reputation as a frontrunner in AI technology innovation, while addressing potential legal and ethical questions related to data sourcing.
The case underscores the increasing intersection of intellectual property rights and artificial intelligence development. As companies accelerate AI advancements, they must navigate complex copyright frameworks to ensure compliance and sustainability. Nvidia’s stance in this legal matter may influence how data usage practices are evaluated and enforced moving forward.
Nvidia rebuffs claims that it used pirated book collections to train AI models, stating no copyright violations occurred in federal court.




